Research
In my second year of undergraduate studies, I conducted research with the iQua Research Group. During this time, I had the opportunity to work on two separate machine learning (ML) related projects.
The first project involved exploring the use of the well-established ML models BERT and XLNet to extract topics from tweets via natural language processing. The key improvement was to utilize the models' word prediction capabilities to determine which "key words" within a given text sample (tweet) carry the most value towards its overall sentiment and meaning.
In the second project we researched improvements to distributed ML using federated learning (FL). Specifically, FL often suffers from degraded quality of model updates after training due to a mixture of low-quality improvements from biased clients, and poor aggregation techniques that don't take client biases into account. To better explore this issue, I created a framework that allows us to easily create a set of specifically biased clients on which to train the federated model.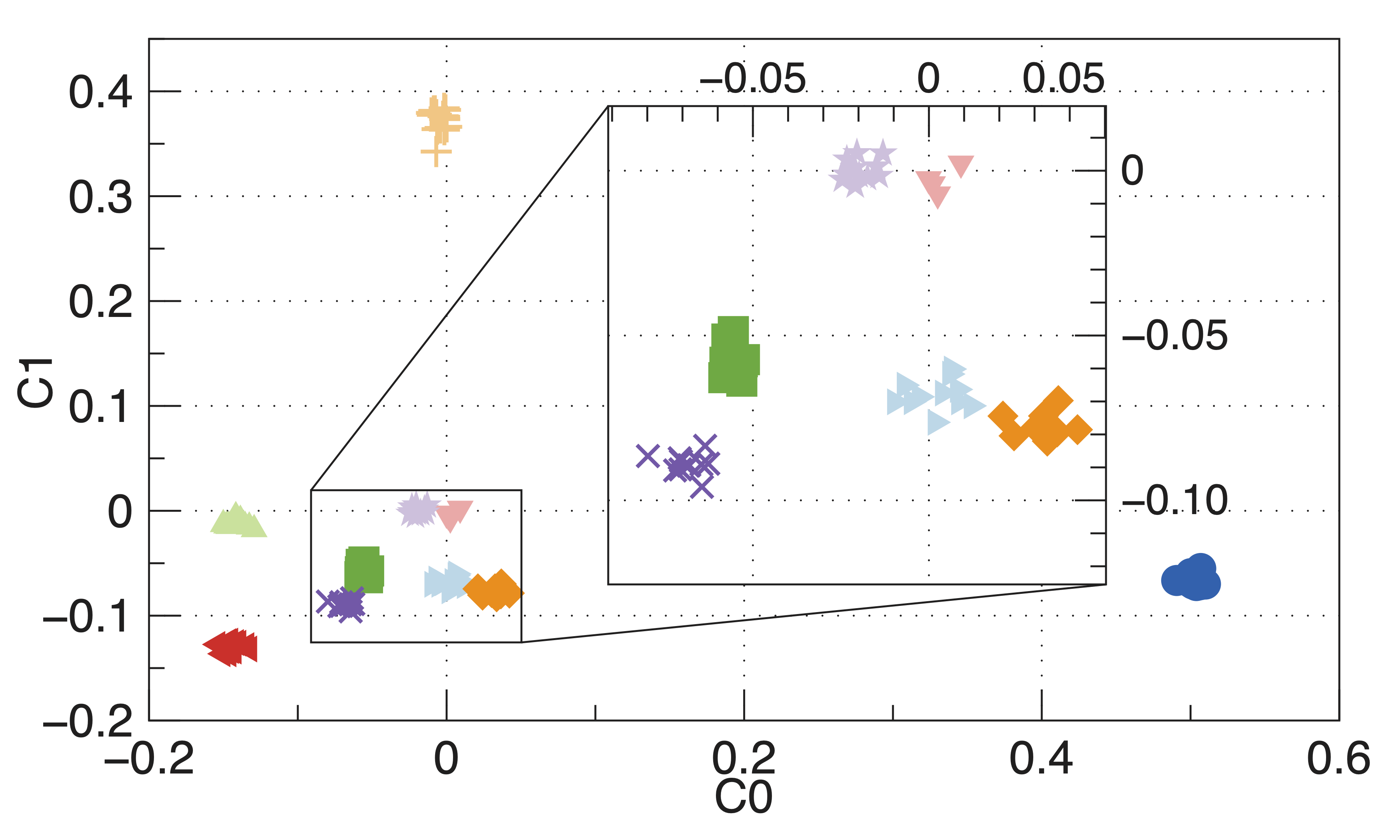
Using this framework, we were able to classify clients into their corresponding bias classes using only their suggested global model updates. These classifications allowed us to build and train a reinforcement learning model to assign weights to each client to improve upon the baseline "federated averaging" algorithm. Our finding from this project were published and presented at the IEEE INFOCOM 2020 conference.